
在做汉化过程中,经常会有一些批量处理的问题。一些简单的操作可以直接使用 Photoshop 解决,稍微复杂的问题使用 Python 的 Pillow 库会更加方便。
Photoshop 提供了一些非常简便的批量处理功能,在窗口—动作中可以通过使用软件预设的动作或者自行录制动作来实现一系列简单的重复动作。
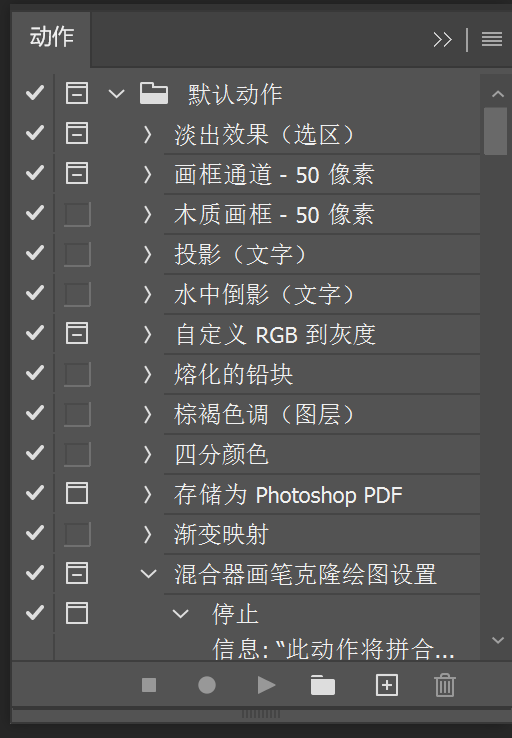
在文件—自动—批处理中,就可以应用这些动作进行批量处理了。但是 Photoshop 自带的批处理并不是非常好用,使用起来局限性较大,效率也不理想。
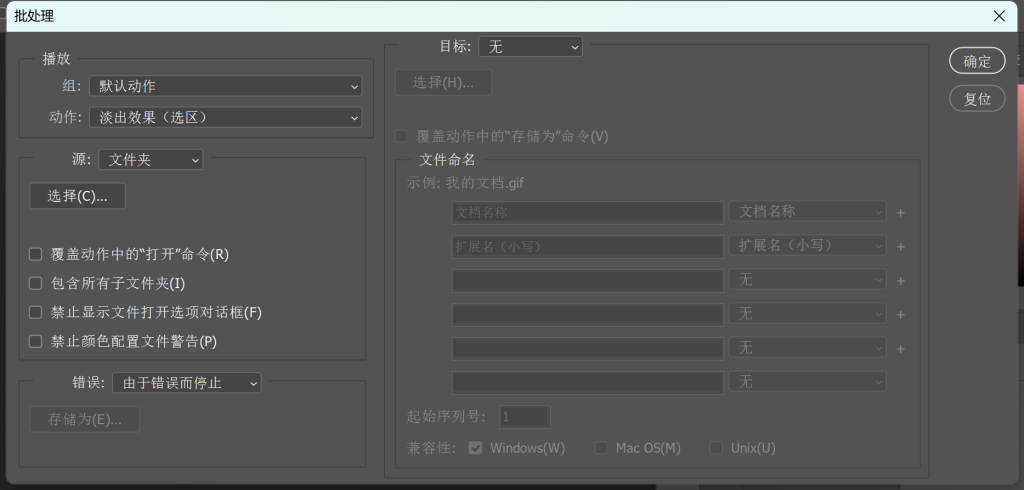
只要熟悉 Python 的 Pillow 库,我们可以很快速的根据需求编写各种批量处理脚本,下面提供几个在实际汉化过程中用到的简单例子作为参考。
使用之前不要忘了安装 Pillow 库:
pip install Pillow
1.裁切并调整尺寸
def resize_and_crop_image(input_path, output_path, target_size):
try:
# 打开图像文件
image = Image.open(input_path)
# 计算缩放比例
width_ratio = target_size[0] / image.width
height_ratio = target_size[1] / image.height
resize_ratio = min(width_ratio, height_ratio)
# 计算缩放后的尺寸
new_width = int(image.width * resize_ratio)
new_height = int(image.height * resize_ratio)
# 缩放图像
image = image.resize((new_width, new_height), Image.ANTIALIAS)
# 计算裁切的位置
left = (new_width - target_size[0]) / 2
top = (new_height - target_size[1]) / 2
right = (new_width + target_size[0]) / 2
bottom = (new_height + target_size[1]) / 2
# 裁切图像
image = image.crop((left, top, right, bottom))
image.save(output_path, dpi=(600, 600))
print(f"已处理文件: {input_path}")
except Exception as e:
print(f"处理文件{input_path}时出错: {str(e)}")
2.整页扫描时分页
def split_image(image_path):
# 打开图片
with Image.open(image_path) as img:
# 获取图片的宽和高
width, height = img.size
# 计算中间位置
middle = width // 2
# 切割图片
left_img = img.crop((0, 0, middle, height))
right_img = img.crop((middle, 0, width, height))
# 获取原始文件名中的两个数字
base_name = os.path.splitext(image_path)[0]
num1, num2 = base_name.split('、')
# 保存切割后的图片
left_img.save(f"{num1}.png")
right_img.save(f"{num2}.png")3.添加图片水印
def add_watermark(input_image_path, output_image_path, watermark_image_path, transparency, scale):
original = Image.open(input_image_path)
watermark = Image.open(watermark_image_path)
watermark = watermark.convert("RGBA")
# 设置透明度
datas = watermark.getdata()
new_data = []
for item in datas:
new_data.append((item[0], item[1], item[2], int(item[3] * transparency)))
watermark.putdata(new_data)
# 缩放
watermark = watermark.resize((int(watermark.width * scale), int(watermark.height * scale)))
# 将水印放在左下角
original.paste(watermark, (0, original.height - watermark.height), watermark)
original.save(output_image_path)4.文字水印
def add_watermark(image_path, watermark_text, output_path):
# 打开图片
image = Image.open(image_path).convert("RGBA")
# 字体和字体大小
font = ImageFont.truetype("C:/Windows/Fonts/arial.ttf", 80)
# 计算水印文字的宽和高
text_width, text_height = ImageDraw.Draw(image).textsize(watermark_text, font)
# 创建一个单独的水印图像
watermark = Image.new('RGBA', (text_width, text_height), (255, 255, 255, 0))
draw = ImageDraw.Draw(watermark)
draw.text((0, 0), watermark_text, font=font, fill=(255, 255, 255, 100))
# 旋转水印图像
watermark = watermark.rotate(45, expand=1)
# 获取图片的宽和高
width, height = image.size
# 创建一个可以在其上进行绘画的图像,初始颜色为透明
txt = Image.new('RGBA', image.size, (255,255,255,0))
# 将旋转后的水印复制到新创建的图像上
for i in range(0, width, watermark.width):
for j in range(0, height, watermark.height):
txt.paste(watermark, (i, j), watermark)
# 合并两个图片
watermarked = Image.alpha_composite(image, txt)
# 将RGBA模式转换为RGB模式
watermarked = watermarked.convert("RGB")
# 保存加了水印的图片
watermarked.save(output_path)